타임 프로파일링
이 챕터에서는 타임 프로파일링 작업을 해보면서 이전에 구현한 Game of Life의 성능을 개선시켜보겠습니다.
시작하기 전에, Rust와 WebAssembly 코드에 사용해 볼 수 있는 타임 프로파일링 툴들을 살펴보셔도 좋습니다.
window.performance.now 함수를 사용하여 초당 프레임 (FPS, Frames Per Second) 타이머 만들기
이 FPS 타이머는 구현한 게임의 렌더링 속도를 어떻게 개선시킬지 살펴볼 때 매우 유용하게 사용될 예정입니다.
wasm-game-of-life/www/index.js 파일에 fps 객체를 추가하는 것으로 시작해 봅시다:
const fps = new class {
constructor() {
this.fps = document.getElementById("fps");
this.frames = [];
this.lastFrameTimeStamp = performance.now();
}
render() {
// 마지막 프레임 렌더부터의 델타 시간을 fps 단위로 변환합니다.
const now = performance.now();
const delta = now - this.lastFrameTimeStamp;
this.lastFrameTimeStamp = now;
const fps = 1 / delta * 1000;
// 마지막 100개의 타이밍만 저장합니다.
this.frames.push(fps);
if (this.frames.length > 100) {
this.frames.shift();
}
// 최대, 최소 타이밍과 마지막 100개 타이밍의 평균을 찾습니다.
let min = Infinity;
let max = -Infinity;
let sum = 0;
for (let i = 0; i < this.frames.length; i++) {
sum += this.frames[i];
min = Math.min(this.frames[i], min);
max = Math.max(this.frames[i], max);
}
let mean = sum / this.frames.length;
// 통계를 렌더합니다.
this.fps.textContent = `
Frames per Second:
latest = ${Math.round(fps)}
avg of last 100 = ${Math.round(mean)}
min of last 100 = ${Math.round(min)}
max of last 100 = ${Math.round(max)}
`.trim();
}
};
fps 객체의 render 함수를 renderLoop 함수의 매 반복마다 호출해 보겠습니다:
const renderLoop = () => {
fps.render(); //new
universe.tick();
drawGrid();
drawCells();
animationId = requestAnimationFrame(renderLoop);
};
마지막으로, fps 요소를 wasm-game-of-life/www/index.html 파일에 잊지 않고 추가해 줍시다. <canvas> 바로 위에 추가해 주세요:
<div id="fps"></div>
CSS 프로퍼티를 추가해서 깔끔하게 포맷해 주겠습니다:
#fps {
white-space: pre;
font-family: monospace;
}
짜잔! 이제 http://localhost:8080 페이지를 새로고침 하면 FPS 카운터를 확인할 수 있게 됐습니다!
Universe::tick의 매 틱을 console.time, console.timeEnd 를 사용하여 측정하기
web-sys 크레이트의 console.time, console.timeend 를 활용하여 각 Universe::tick이 호출되는데 걸리는 시간을 확인해 볼 수 있습니다.
먼저, wasm-game-of-life/Cargo.toml 파일을 열고 web-sys 를 종속성으로 추가해 주세요:
[dependencies.web-sys]
version = "0.3"
features = [
"console",
]
console.time를 호출할 때마다 console.timeEnd도 같이 호출될 예정이기 때문에, RAII 타입으로 묶어서 간편하게 사용 할 수도 있습니다:
#![allow(unused)] fn main() { extern crate web_sys; use web_sys::console; pub struct Timer<'a> { name: &'a str, } impl<'a> Timer<'a> { pub fn new(name: &'a str) -> Timer<'a> { console::time_with_label(name); Timer { name } } } impl<'a> Drop for Timer<'a> { fn drop(&mut self) { console::time_end_with_label(self.name); } } }
그다음, 메소드 최상단에 다음 코드를 추가해서 각 Universe::tick 호출이 얼마나 오래 걸리는지 측정해 볼 수 있습니다:
#![allow(unused)] fn main() { let _timer = Timer::new("Universe::tick"); }
콘솔에 Universe::tick를 호출하는 데 걸리는 시간을 로그로 표시합니다:
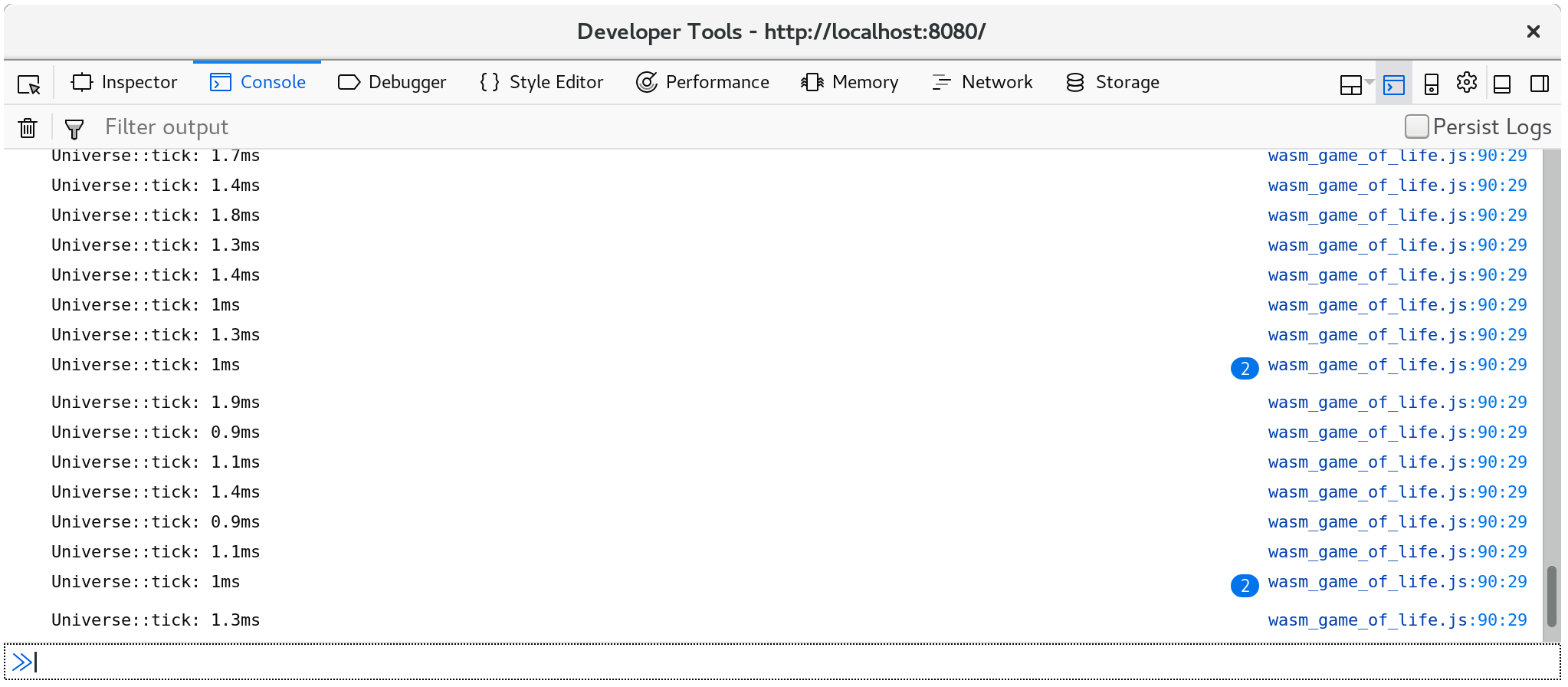
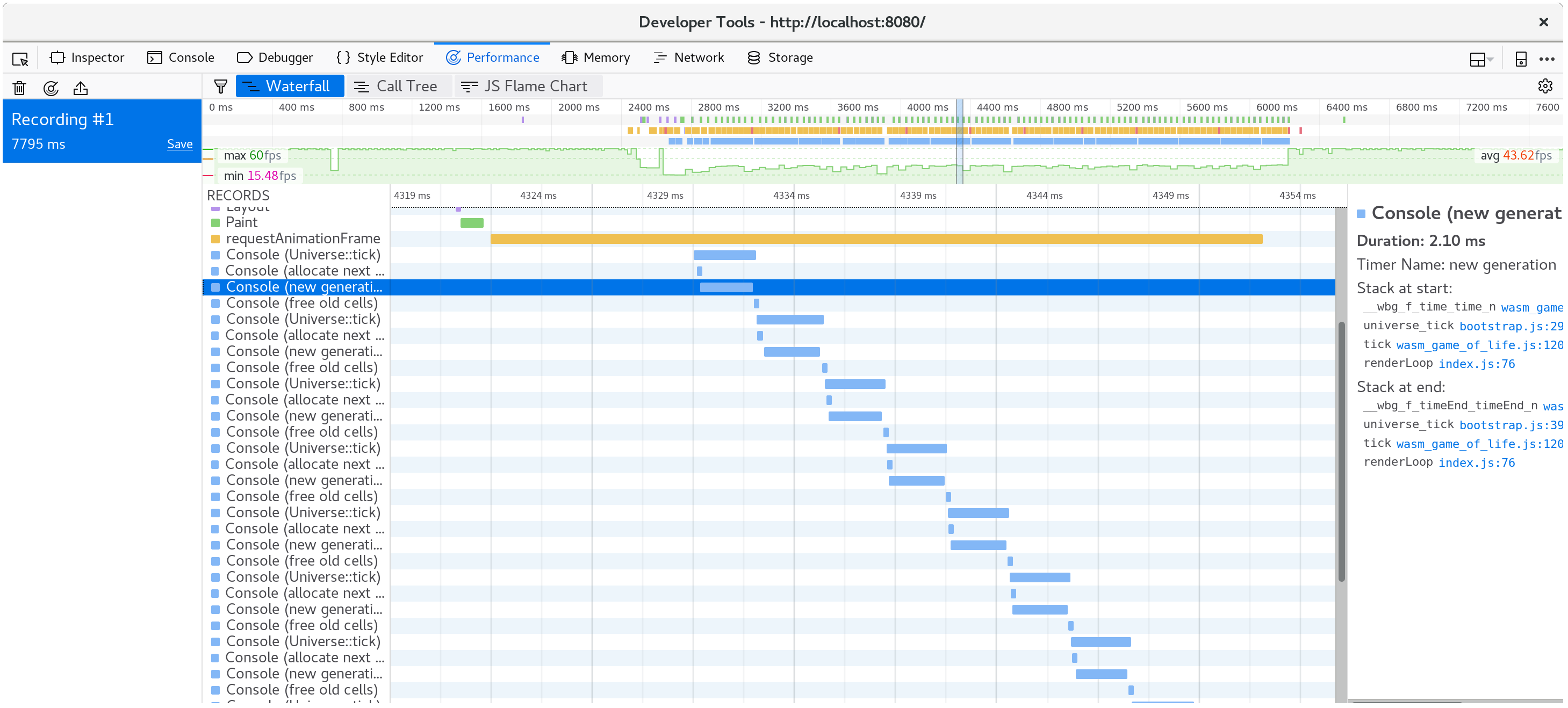
추가로, 브라우저 프로파일러(profiler)의 timeline 혹은 waterfall 뷰에서 console.time과 console.timeEnd가 같이 실행된 부분을 확인할 수 있습니다:
Game of Life 세상의 사이즈 늘려보기
⚠️ 이 섹션은 FireFox의 스크린샷을 예시로 보여줍니다. 거의 모든 모던 브라우저가 비슷한 기능들을 가지고 있지만, 브라우저마다 개발자 도구에 약간의 차이가 있을 수는 있습니다. 뜯어보게 될 프로파일 정보는 기본적으로 같지만, 보게 될 뷰나 도구 이름 등이 살짝 다를 수 있는 점을 미리 확인해 주세요.
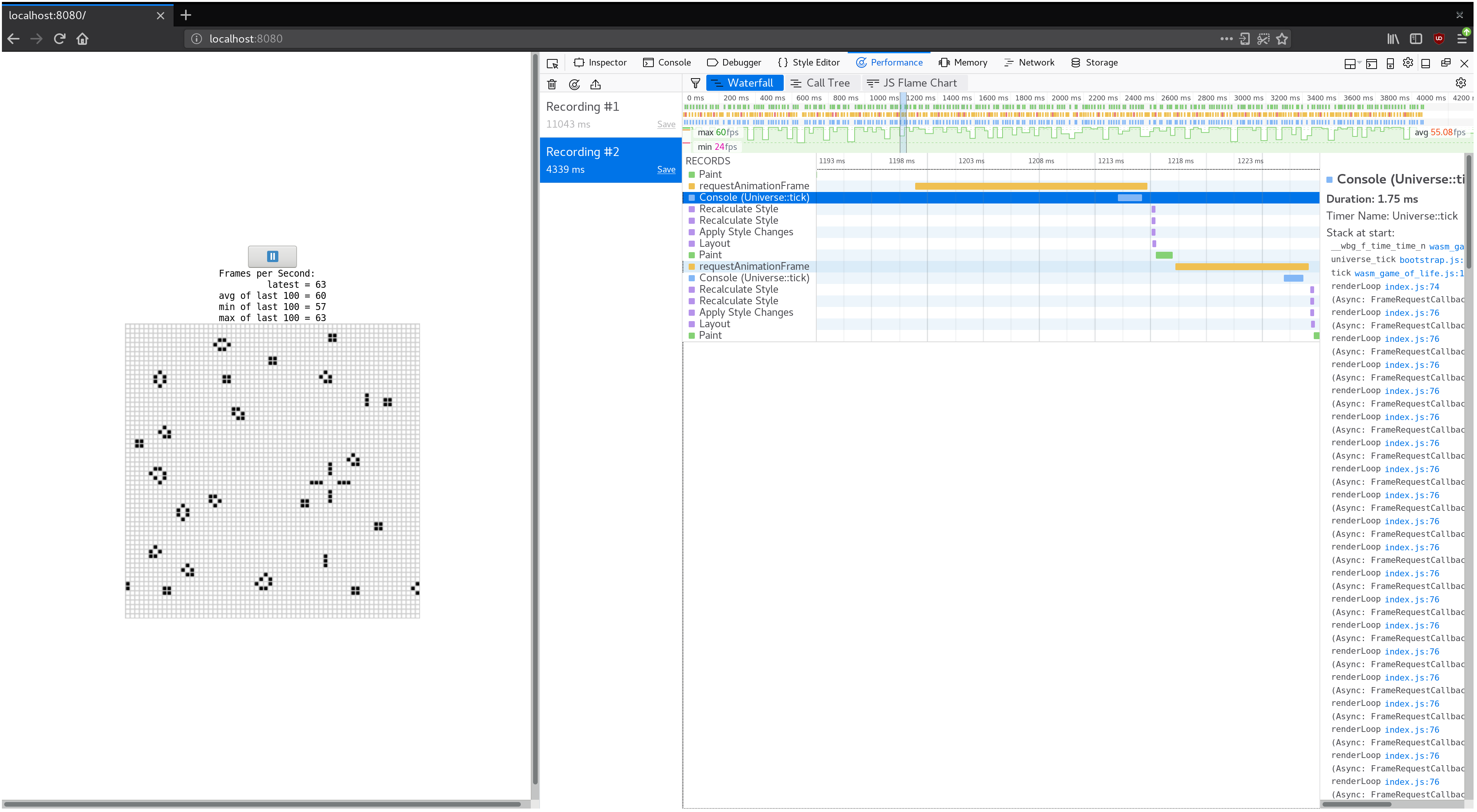
구현한 Game of Life 세상을 더 크게 만들어보면 어떨까요? 64 x 64 사이즈의 세상을 128 x 128 사이즈로 늘려봅시다. (wasm-game-of-life/src/lib.rs 파일에서 Universe::new를 수정해 주세요.) 제 컴퓨터에서는 사이즈를 늘렸을 때 부드럽게 작동하던 60fps 화면이 버벅이면서 40fps 처럼 보이는 부분이 확인됩니다.
프로파일을 기록하고 waterfall 뷰를 확인하면, 각 애니메이션이 처리되는데 20 밀리초보다 더 많이 걸리는 것을 확인할 수 있습니다. 60fps로 표시됐을 때는 프레임 전체를 렌더하는데 16 밀리초가 걸린 것을 떠올려보면 확실히 차이가 있는 것 같습니다. 참고로, JavaScript와 WebAssembly외에도 페이지를 그리는 등 브라우저가 수행하는 다른 작업의 영향도 있으니 참고해 주세요.
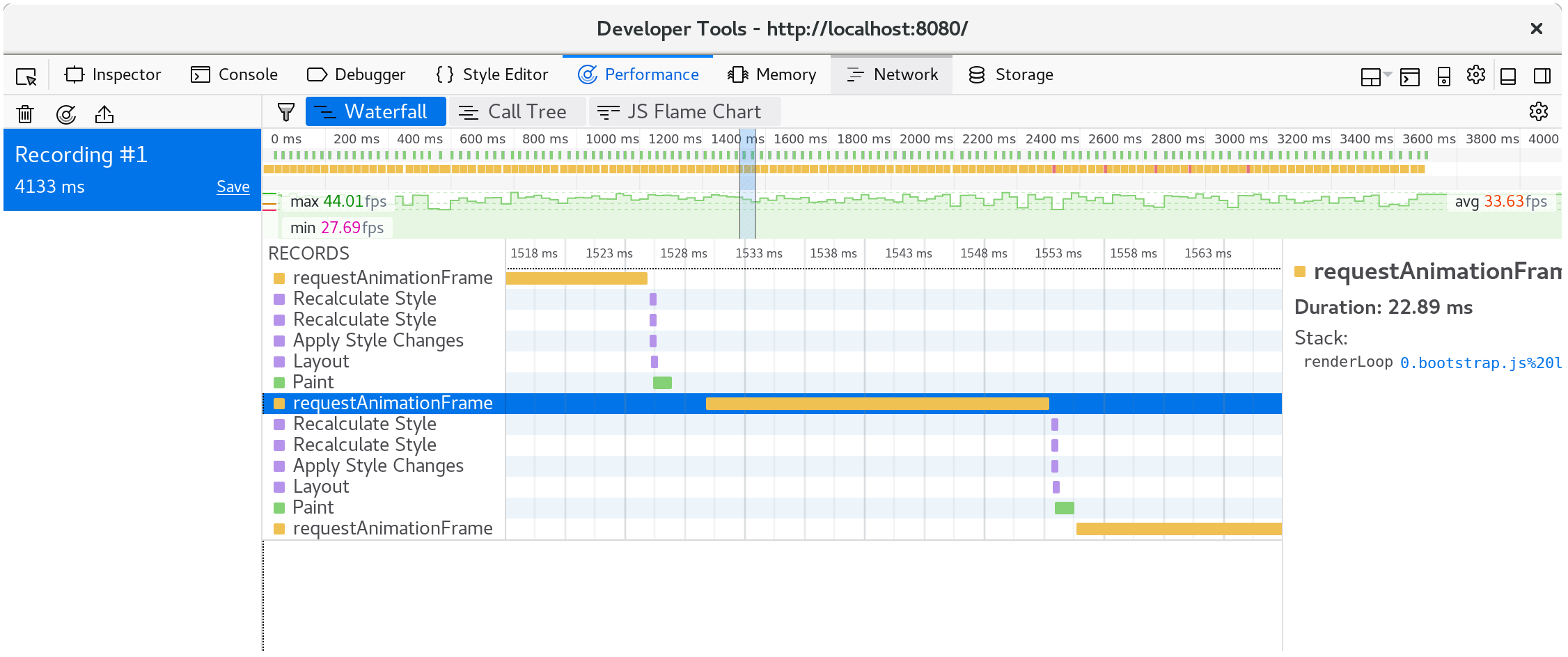
한 애니메이션 프레임 동안 어떤 일이 일어나는지 잘 확인해 보면, CanvasRenderingContext2D.fillStyle의 setter가 많은 성능을 요구하는 부분을 확인할 수 있습니다.
⚠️ FireFox 브라우저에서 위 내용에서 언급된
CanvasRenderingContext2D.fillStyle대신에 "DOM"이 표시된다면 성능 개발자 도구 (performance developer tools) 에서 "Gecko 플랫폼 데이터 표시하기 (Show Gecko Platform Data)" 옵션을 활성화해줘야 할수도 있습니다:
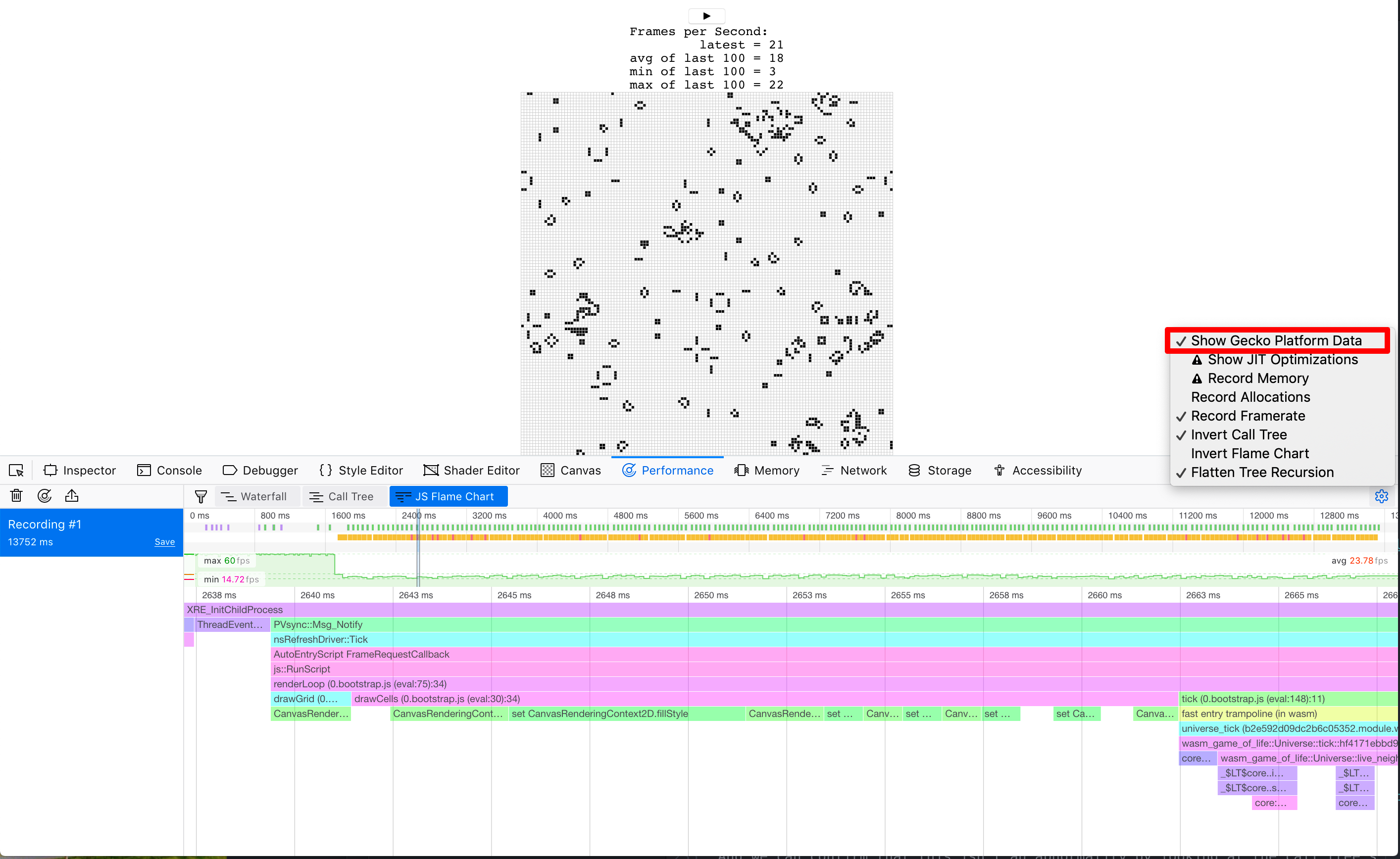
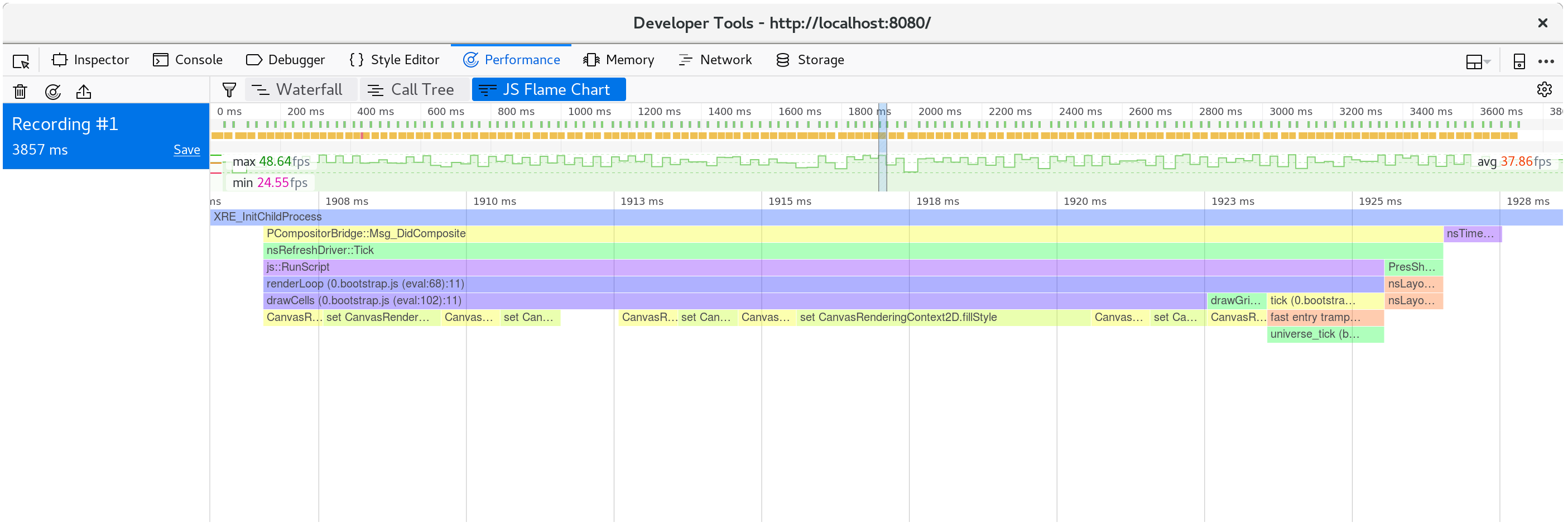
많은 프레임의 호출 트리 집계 (call tree's aggregation) 를 살펴보면 이게 전혀 이상한 동작이 아님을 확인할 수 있습니다:
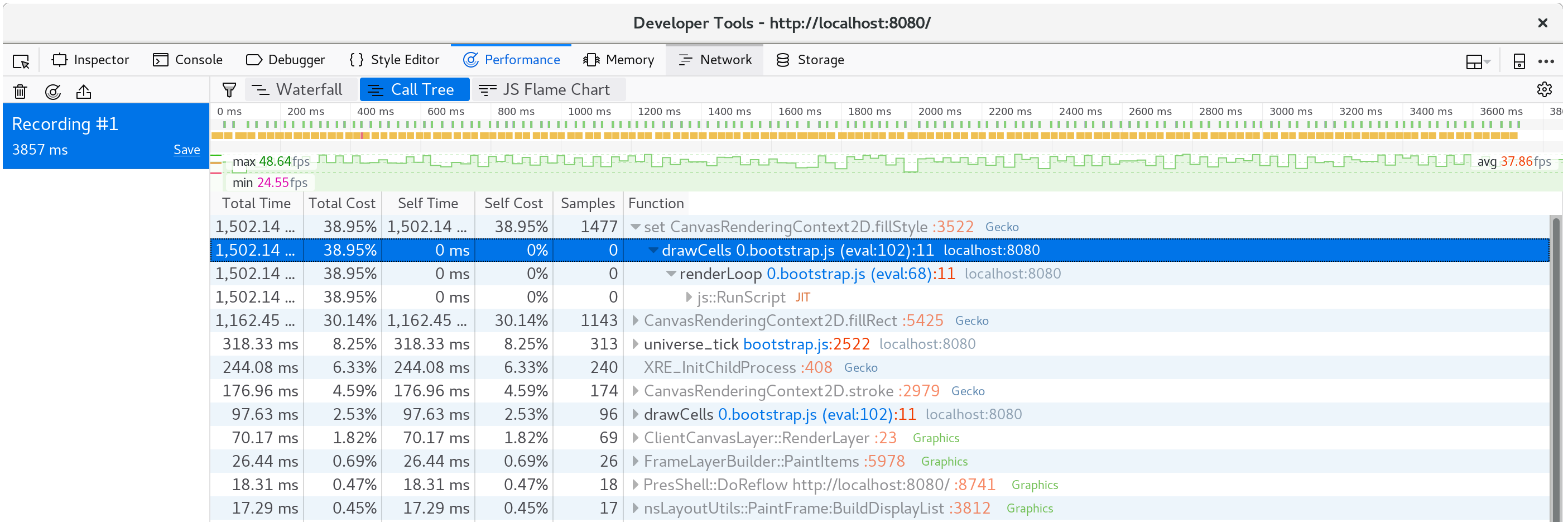
어이쿠! 거의 40% 분량을 이 setter에 사용해버렸네요!
⚡
tick메소드가 성능 병목을 일으키는데 특별한 이유가 있을 것 같았지만, 사실 그렇지 않은 부분을 확인했습니다. 이렇게 작업을 하다 보면 예상치 못한 부분에서 시간을 많이 쓰게 될 수도 있으니, 항상 정말 중요한 프로파일링 도구를 먼저 살펴보도록 합시다.
wasm-game-of-life/www/index.js 파일 내의 drawCells 함수에서 fillStyle 프로퍼티가 한번 정해지면 세상 내의 모든 세포와 모든 애니메이션에 이 프로퍼티가 사용되게 됩니다.
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
ctx.fillStyle = cells[idx] === DEAD
? DEAD_COLOR
: ALIVE_COLOR;
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
fillStyle가 많은 성능을 요구하는 부분을 확인했는데, 그렇다면 어떤 식으로 코드를 작성해서 개선시킬수 있을까요? 세포의 생존 여부에 따라 fillStyle를 사용하도록 바꿔봅시다. fillStyle = ALIVE_COLOR를 추가해 줘서 살아있는 세포만 그리도록 하고 fillStyle = DEAD_COLOR도 추가해 줘서 죽은 세포도 동일한 방식으로 처리를 해준다면 세포들을 모두 한 번에 그리는 대신 fillStyle을 두 번만 설정하게 됩니다.
// 살아있는 세포들을 처리합니다.
ctx.fillStyle = ALIVE_COLOR;
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
if (cells[idx] !== Cell.Alive) {
continue;
}
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
// 죽어있는 세포들을 처리합니다.
ctx.fillStyle = DEAD_COLOR;
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
if (cells[idx] !== Cell.Dead) {
continue;
}
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
코드 파일을 저장하고 http://localhost:8080/ 페이지를 새로고침 해주면, 웹사이트가 60fps로 다시 부드럽게 렌더 됩니다.
프로파일을 다시 확인해 보면, 각 애니메이션 프레임마다 오직 10 밀리초만 걸리는 부분도 확인할 수 있습니다.
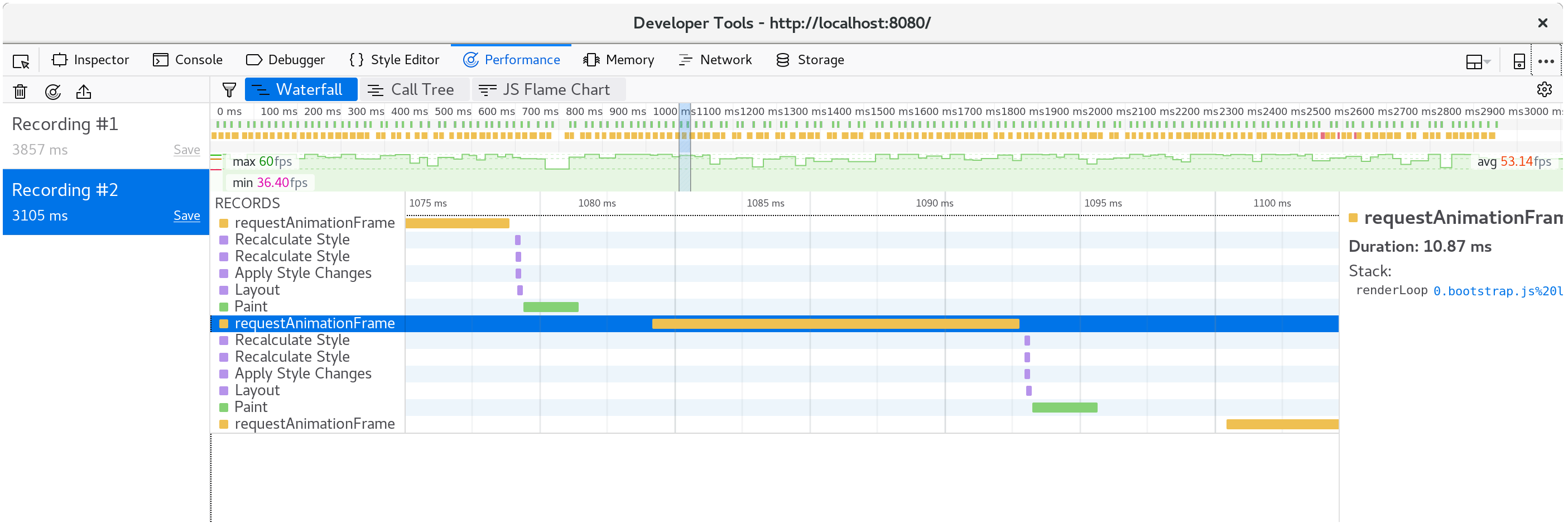
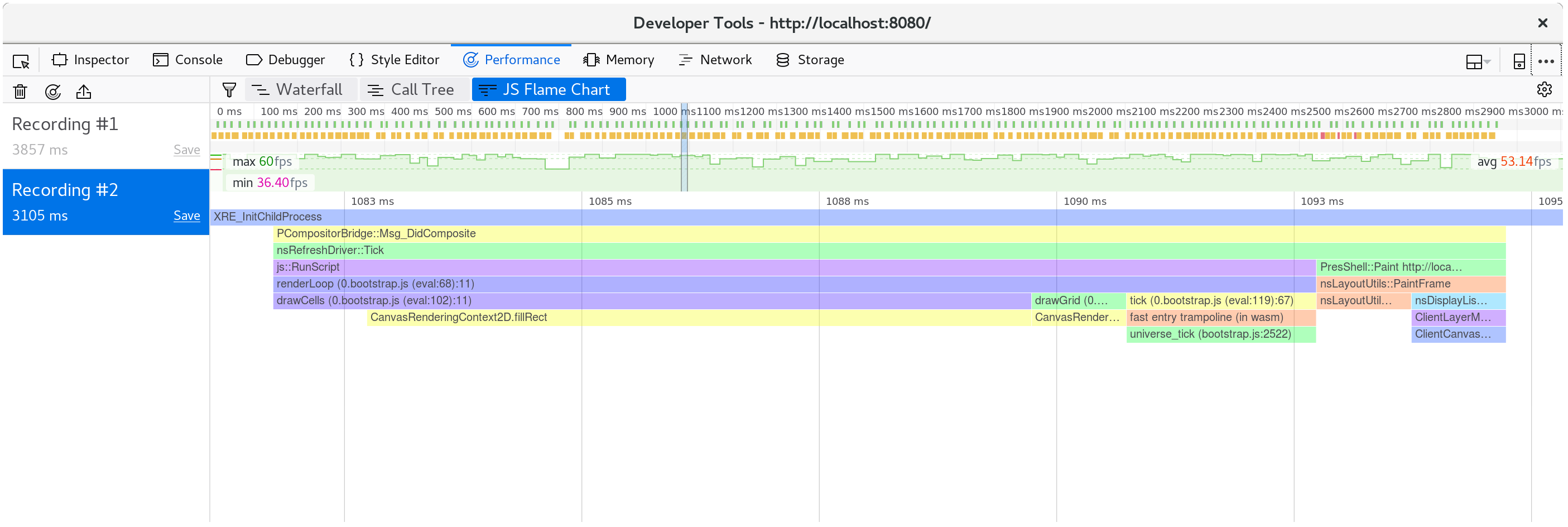
한 프레임을 다시 분석해 보면, fillStyle 이 더 이상 성능을 많이 사용하지 않고, fillRect가 각 세포 사각형을 그리는데 대부분의 시간이 소비되는 것을 확인할 수 있습니다.
Game of Life가 더 빠르게 진행되도록 만들어보기
어떤 사람들은 빨리빨리 진행하는 것을 선호해서 매 프레임마다 1틱이 아니라 9틱씩 진행되도록 수정하고 싶을 수도 있습니다. 놀랍게도 이 작업은 wasm-game-of-life/www/index.js 파일의 renderLoop 함수를 수정해서 생각 외로 간단하게 해볼 수 있습니다:
for (let i = 0; i < 9; i++) {
universe.tick();
}
제 컴퓨터에서 구현한 게임이 35fps 속도로 다시 느려진 것 같습니다. 좋지 않은 현상이니 다시 60fps 로 만들어보겠습니다!
잘 확인해보면 Universe::tick 에서 시간이 많이 소요되는 것으로 보입니다. Timer를 추가해서 console.time과 console.timeEnd 호출을 감싸고 다시 한번 살펴보겠습니다. 제 예상대로라면 매 틱마다 세포의 새 벡터를 할당하고 기존 벡터를 해제(freeing)하는 작업은 많은 성능을 사용할 뿐 아니라 시간도 많이 소비하게 될것 같습니다.
#![allow(unused)] fn main() { pub fn tick(&mut self) { let _timer = Timer::new("Universe::tick"); let mut next = { let _timer = Timer::new("다음 세포들을 할당합니다."); self.cells.clone() }; { let _timer = Timer::new("다음 세대를 처리합니다."); for row in 0..self.height { for col in 0..self.width { let idx = self.get_index(row, col); let cell = self.cells[idx]; let live_neighbors = self.live_neighbor_count(row, col); let next_cell = match (cell, live_neighbors) { // 규칙 1: 인구 부족으로 2개 미만의 이웃을 가진 세포는 죽게 됩니다. (Cell::Alive, x) if x < 2 => Cell::Dead, // 규칙 2: 2개 혹은 3개의 이웃을 가진 세포는 다음 세대에서 계속 살아있습니다. (Cell::Alive, 2) | (Cell::Alive, 3) => Cell::Alive, // 규칙 3: 과잉 인구로 3개 초과의 이웃을 가진 모든 세포는 죽게 됩니다. (Cell::Alive, x) if x > 3 => Cell::Dead, // 규칙 4: 세포 증식으로 정확히 3개의 이웃을 가진 세포는 살아나게 됩니다. (Cell::Dead, 3) => Cell::Alive, // 규칙이 적용되지 않는 세포들의 상태는 그대로 유지되게 됩니다. (otherwise, _) => otherwise, }; next[idx] = next_cell; } } } let _timer = Timer::new("기존 세포들을 해제합니다."); self.cells = next; } }
브라우저 개발자 도구에서 타이밍(timing)을 잘 확인해 보면 이 예상이 사실은 명백하게 틀린 부분을 확인할 수 있습니다. 실제로는 대부분의 시간이 다음 세대 세포들을 계산하는데 사용되게 됩니다. 그리고 의외로 매 틱마다 벡터 값을 할당하고 해제하는 작업이 그렇게 성능을 많이 사용하지 않습니다. 다시 한번 정말 중요한 프로파일링을 해보겠습니다!
사용하게 될 테스트 기능 게이트 (test feature gate) 가 nightly 버전에 같이 포함돼 있기 때문에, nightly 컴파일러가 필요합니다. 그러면 벤치마킹에 이 기능을 한번 사용해 보겠습니다. cargo benchcmp이라는 툴도 필요하니 설치해 주도록 합시다. 참고로 cargo benchcmp는 cargo bench로 생성한 마이크로 벤치마킹을 비교하는 데 사용하는 작은 사이즈의 유틸리티입니다.
WebAssembly와 동일한 작업을 수행하는 네이티브 코드인 #[bench]를 작성해 봅시다. 이렇게 네이티브 코드를 작성하게 되면 더 많은 기능을 사용할 수 있게 됩니다. 이제 새롭게 작성된 wasm-game-of-life/benches/bench.rs을 확인해 보겠습니다:
#![allow(unused)] #![feature(test)] fn main() { extern crate test; extern crate wasm_game_of_life; #[bench] fn universe_ticks(b: &mut test::Bencher) { let mut universe = wasm_game_of_life::Universe::new(); b.iter(|| { universe.tick(); }); } }
#[wasm_bindgen] 속성을 모두 주석 처리 해주도록 하고, Cargo.toml 파일의 "cdylib"도 주석 처리 해주겠습니다. 이렇게 주석 처리를 하지 않으면 빌드가 실패하고 링크 오류(link errors)가 발생하게 됩니다.
준비가 다 됐다면, cargo bench | tee before.txt 명령어를 실행해서 코드를 컴파일하고 벤치마크를 실행해 보겠습니다. | tee before.txt를 포함하면서 cargo bench 명령어의 출력값을 가져와서 before.txt 파일에 저장할 예정이니 이 부분도 다시 확인해 주세요.
$ cargo bench | tee before.txt
Finished release [optimized + debuginfo] target(s) in 0.0 secs
Running target/release/deps/wasm_game_of_life-91574dfbe2b5a124
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/release/deps/bench-8474091a05cfa2d9
running 1 test
test universe_ticks ... bench: 664,421 ns/iter (+/- 51,926)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
여기서 바이너리 파일의 경로도 같이 표시되는 부분을 확인할 수 있습니다. 이번에는 운영체제의 프로파일러를 사용하여 벤치마킹을 다시 한번 해보겠습니다. 저는 리눅스(Linux)를 사용하고 있으니 perf를 예제로 사용하겠습니다:
$ perf record -g target/release/deps/bench-8474091a05cfa2d9 --bench
running 1 test
test universe_ticks ... bench: 635,061 ns/iter (+/- 38,764)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.178 MB perf.data (2349 samples) ]
perf report 명령어로 프로파일을 로드하면, 예상한 대로 대부분의 시간이 Universe::tick를 실행하는데 소비되는 것을 확인할 수 있습니다:
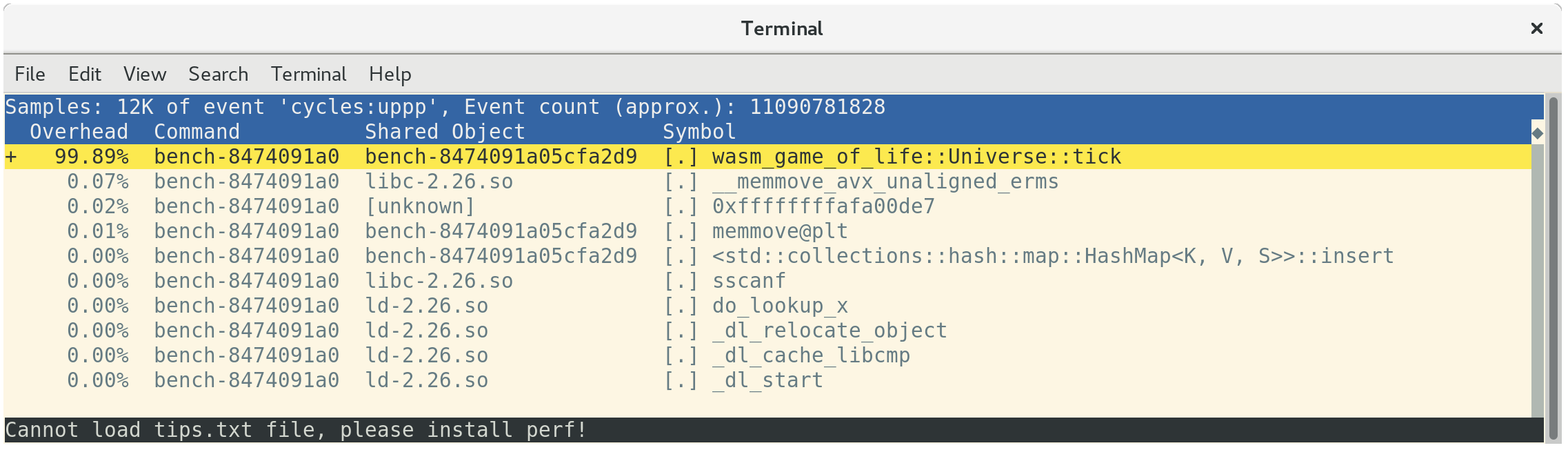
perf를 실행한 다음 a 키를 누르면 어떤 어셈블리 명령어(instruction)이 함수를 처리할 때 사용되고 있는지 확인할 수 있습니다:
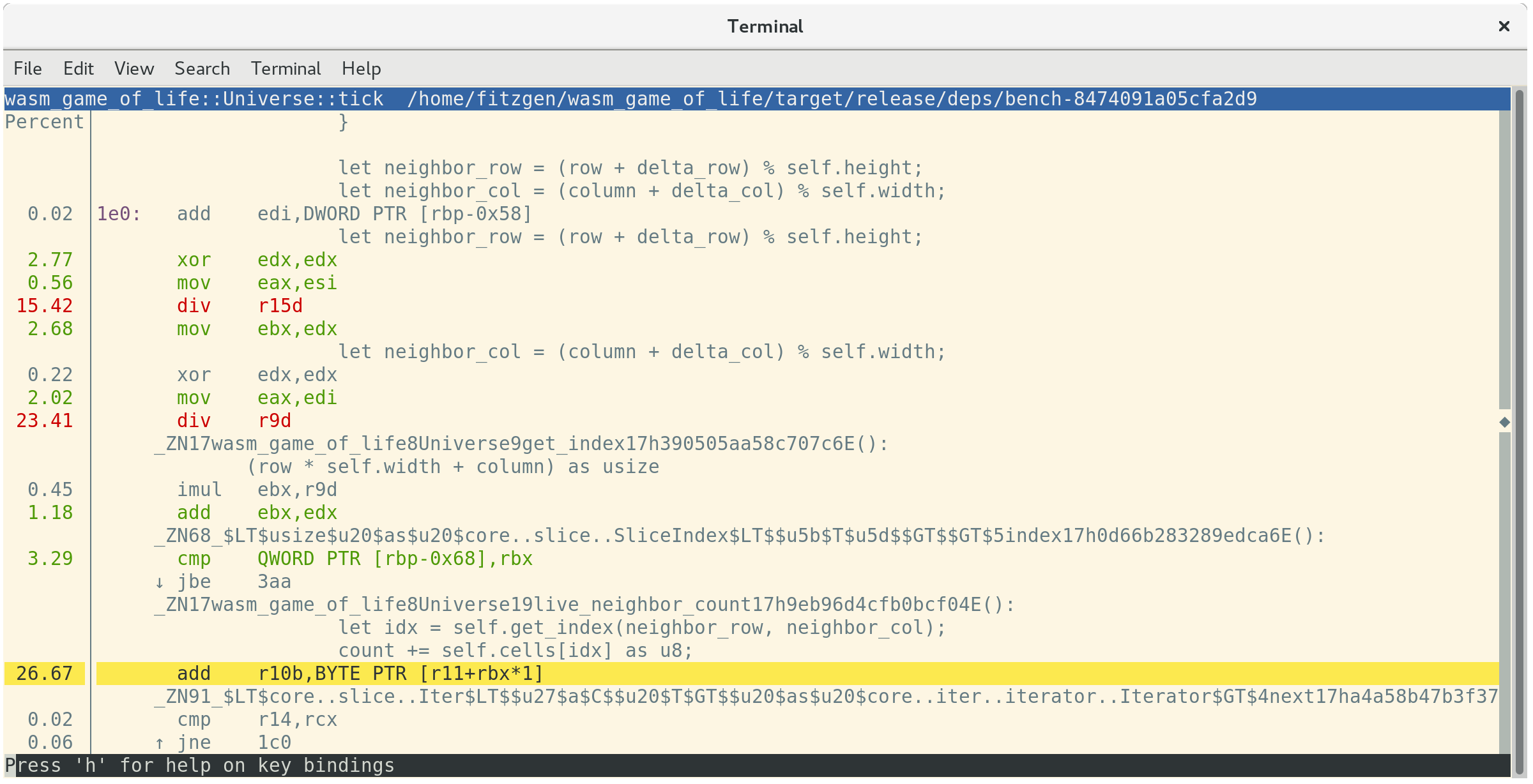
위 내용을 확인하면 26.67%의 시간이 이웃 세포들을 만들어내는 데 사용되고, 23.41%를 이웃들의 열 인덱스, 그리고 나머지 15.42%를 행 인덱스를 더하는 데 사용되는 것을 알 수 있습니다. 제일 많은 성능을 사용하는 세 명령어들 중, 두 번째와 세 번째로 비용이 많이 드는 명령어가 div 명령어인 부분도 확인할 수 있습니다. 이 div 구현들이 Universe::live_neighbor_count 함수에서 나머지 연산자로 인덱싱 하도록 구현했던 부분입니다. (modulo indexing logic)
wasm-game-of-life/src/lib.rs 파일에서 live_neighbor_count를 정의했던 내용을 다시 떠올려봅시다:
#![allow(unused)] fn main() { fn live_neighbor_count(&self, row: u32, column: u32) -> u8 { let mut count = 0; for delta_row in [self.height - 1, 0, 1].iter().cloned() { for delta_col in [self.width - 1, 0, 1].iter().cloned() { if delta_row == 0 && delta_col == 0 { continue; } let neighbor_row = (row + delta_row) % self.height; let neighbor_col = (column + delta_col) % self.width; let idx = self.get_index(neighbor_row, neighbor_col); count += self.cells[idx] as u8; } } count } }
코드를 다시 확인해 보면 if 블럭들로 첫째와 마지막 행과 열의 엣지 케이스(edge case) 를 처리하는데 코드를 불필요하게 길게 작성하는 대신 나머지 연산자 (modulo operator) 를 사용하고 있는 부분을 확인할 수 있습니다. row과 column 둘 다 세상의 가장자리에 있지 않고 나머지 연산자를 쓸 필요가 없는 일반적인 경우를 처리하는데도 div 명령어를 사용해서 많은 성능을 사용하는 부분도 확인됩니다. 반복문을 사용하는 대신에 if 문으로 이러한 엣지 케이스들을 처리하고, 여러 분기들을 CPU의 분기 예측기(branch predictor)가 예측하기 쉽도록 만들어보겠습니다.
live_neighbor_count를 다음과 같이 다시 작성해 봅시다:
#![allow(unused)] fn main() { fn live_neighbor_count(&self, row: u32, column: u32) -> u8 { let mut count = 0; let north = if row == 0 { self.height - 1 } else { row - 1 }; let south = if row == self.height - 1 { 0 } else { row + 1 }; let west = if column == 0 { self.width - 1 } else { column - 1 }; let east = if column == self.width - 1 { 0 } else { column + 1 }; let nw = self.get_index(north, west); count += self.cells[nw] as u8; let n = self.get_index(north, column); count += self.cells[n] as u8; let ne = self.get_index(north, east); count += self.cells[ne] as u8; let w = self.get_index(row, west); count += self.cells[w] as u8; let e = self.get_index(row, east); count += self.cells[e] as u8; let sw = self.get_index(south, west); count += self.cells[sw] as u8; let s = self.get_index(south, column); count += self.cells[s] as u8; let se = self.get_index(south, east); count += self.cells[se] as u8; count } }
벤치마킹을 다시 해보겠습니다! 이번에는 출력되는 메세지들을 after.txt로 출력해 봅시다.
$ cargo bench | tee after.txt
Compiling wasm_game_of_life v0.1.0 (file:///home/fitzgen/wasm_game_of_life)
Finished release [optimized + debuginfo] target(s) in 0.82 secs
Running target/release/deps/wasm_game_of_life-91574dfbe2b5a124
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/release/deps/bench-8474091a05cfa2d9
running 1 test
test universe_ticks ... bench: 87,258 ns/iter (+/- 14,632)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
훨씬 나은 것 같습니다! benchcmp 툴과 방금 생성한 두 텍스트 파일을 확인해 보면 얼마나 나이졌는지 볼 수 있습니다:
$ cargo benchcmp before.txt after.txt
name before.txt ns/iter after.txt ns/iter diff ns/iter diff % speedup
universe_ticks 664,421 87,258 -577,163 -86.87% x 7.61
우와! 7.61 배나 빨라졌네요!
WebAssembly는 의도적으로 일반적인 하드웨어 아키텍처와 밀접하게 매핑(mapping)되도록 설계돼 있지만, 이러한 네이티브 코드의 속도 향상이 WebAssembly 성능 향상으로도 이어질 수 있는지 확실히 확인해 보는 것도 중요합니다.
wasm-pack build 명령어를 실행해서 .wasm 파일을 다시 빌드하고 http://localhost:8080/ 페이지를 새로고침 해주세요. 제 컴퓨터에서는 60 fps의 속도로 다시 작동하는 것이 확인됩니다. 브라우저의 프로파일러를 사용해서 다시 확인해 보니 각 애니메이션 프레임이 10 밀리초씩 걸리는 것으로 확인됩니다.
성공적으로 잘 마무리한 것 같습니다!
연습해 보기
-
현재로는 할당과 해제를 처리하는 코드를 지우는 게
Universe::tick속도를 향상시키는 가장 쉬운 방법입니다.Universe가 두 벡터만 관리하도록 하고, 두 벡터를 코드가 실행되는 내내 해제되거나tick함수에서 새 버퍼를 할당하지 않도록 세포들을 이중 버퍼링 (double buffering) 기법으로 구현해 보세요. -
"Game of Life 구현하기" 섹션에서 델타 기반으로 설계한 내용을 토대로, Rust 코드가 상태가 바뀐 세포들의 목록을 반환하는 방식으로 다시 코드를 설계해 보세요.
<canvas>가 더 빨리 렌더되는 게 보이시나요? 매 틱마다 새 델타 목록을 할당하지 않으면서 구현하실수 있을것 같으신가요? -
프로파일링 툴로 확인할 수 있듯, 2D
<canvas>렌더링이 특별히 빠르지는 않은 것 같습니다. 2D 캔버스 렌더러 대신 WebGL 렌더러를 대신 사용해서 코드를 다시 구현해 보세요. WebGL로 구현한 버전은 얼마나 더 빠른가요? 답답하게 느렸던 WebGL과 비교하면 얼마나 큰 사이즈의 세상을 가볍게 처리할 수 있게 됐나요?